 |  | Nico Kibria |
| | Christina Lamers |
 |
12.02.2023 08:00 Uhr |
Viele Jahrzehnte war die Entwicklung von Peptidarzneistoffen geprägt von der Identifizierung und Isolierung natürlicher Peptide. Im Vergleich zu niedermolekularen Wirkstoffen etablierte sich die rationale Entwicklung von Peptidarzneistoffen aufgrund ihrer hohen strukturellen Komplexität langsam.
Die Fortschritte in der Strukturaufklärung der letzten Jahrzehnte ermöglichen jetzt die rationale Entwicklung von Peptiden, die sich von Proteinsekundärstrukturen ableiten. Häufig handelt es sich um Inhibitoren sogenannter Protein-Protein-Interaktionen, beispielsweise die Tumorsuppressor-Interaktion von MDMX/p53 durch ALRN-6924 (in PhaseII). Hierbei werden Strukturelemente eines Proteins, zum Beispiel α-Helices, die maßgeblich an einer Protein-Interaktion zur Bildung des funktionellen Multiproteinkomplexes beteiligt sind, mittels synthetischer Peptide nachgeformt. Somit wird die Interaktion der beiden Proteine kompetitiv durch das Peptid gehemmt, was im Fall von MDMX/p53 zur Freisetzung des Tumorsuppressors p53 und somit zur Einleitung der Apoptose führt.
Ein gänzlich neuer Ansatz sind Technologien, die aus einer großen Substanzbibliothek potenzielle Wirkstoffkandidaten herausfiltern. Hervorzuheben sind Methoden, die eine genetische Codierung der Peptidsequenz nutzen und somit die Selektion einer Hit-Substanz aus Millionen Substanzen ermöglichen.
Das Phagen-Display wurde 1982 von George P. Smith und Greg Winter entwickelt und ursprünglich zur Identifizierung und Entwicklung von Antikörpern genutzt (18). Wie funktioniert diese Methode?
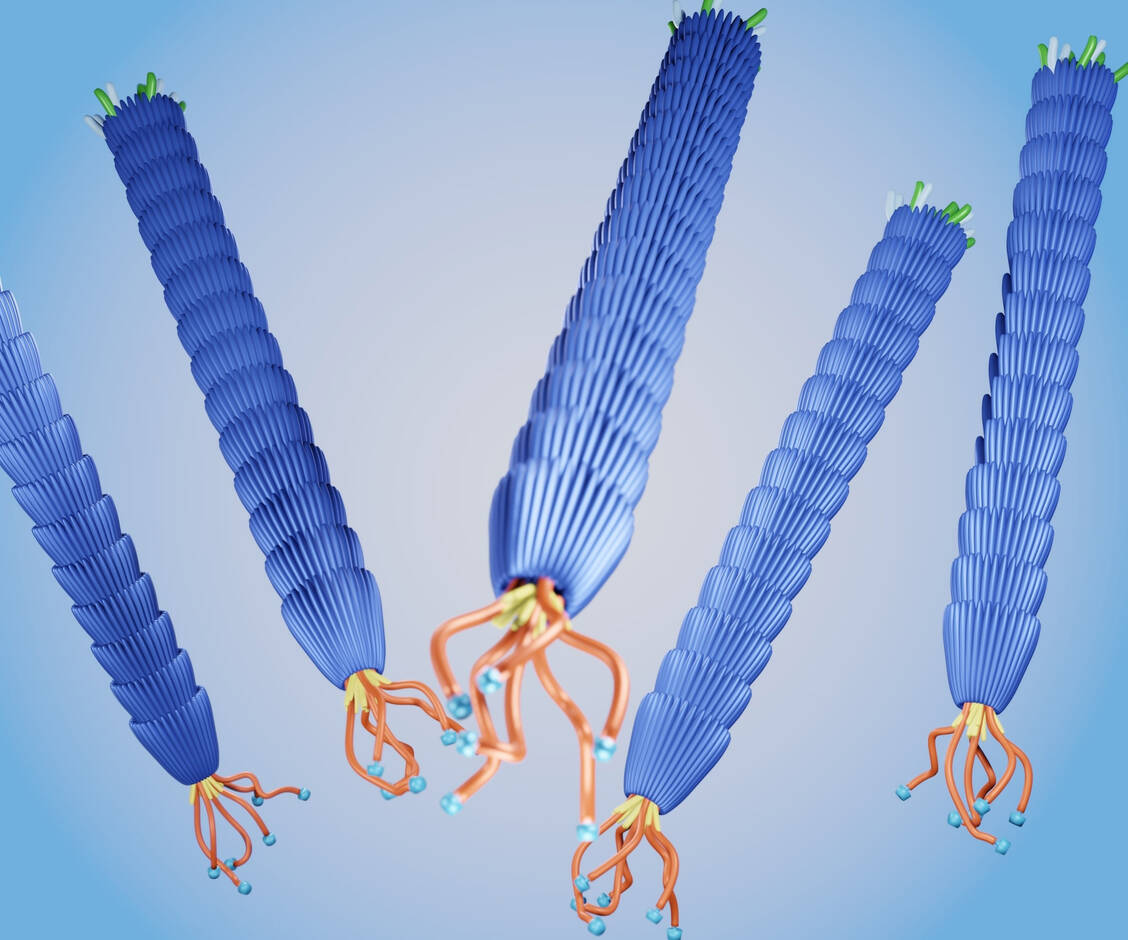
Bakteriophagen wie die abgebildeten M13-Phagen sind wichtige Helfer bei der Suche nach neuen Peptidarzneistoffen. / Foto: Shutterstock/Love Employee
Zunächst werden in die DNA von Phagen (Bakterienviren) Basensequenzen eingefügt, die für eine große Vielfalt von potenziell interessanten Antikörpern oder Peptiden codieren. Diese Sequenzen werden so eingefügt, dass die Peptide mit einem Hüllprotein des Phagen verknüpft sind und somit auf dessen Oberfläche präsentiert werden. An jeder Position der Sequenz kann jede der proteinogenen 20 Aminosäuren eingefügt werden, sodass jede mögliche Kombination in der Bibliothek enthalten ist. Nach Infektion von Bakterien (E. coli) durch die modifizierten Phagen werden diese in E. coli vervielfältigt und im Anschluss aufgereinigt.
Die Phagen-Protein-Bibliothek wird nun mit einem Zielprotein, das immobilisiert vorliegt, zum Beispiel einem Rezeptor, inkubiert. Aus der Vielzahl der exprimierten diversen Peptide können einige an das immobilisierte Target andocken – das sind die gesuchten Sequenzen; nicht-bindende Phagen werden weggewaschen. Durch eine erneute Vervielfältigung der bindenden Phagen können interessante Peptidkandidaten angereichert und anschließend kann durch Sequenzierung der Phagen-DNA die Sequenz des Peptids identifiziert werden.
Eine ähnliche In-vitro-Selektionsmethode verwendet mRNA als genetischen Informationsträger der Peptidbibliothek. Bei dieser Methode, dem mRNA-Display, wird die mRNA während der Translation kovalent an das gerade gebildete Peptid gebunden. Die Selektion erfolgt wieder gegen ein immobilisiertes Protein und die Sequenzierung der mRNA ermöglicht die Identifizierung des gesuchten Peptids (19). Da hierbei kein lebendes System (wie E.coli), sondern nur aufgereinigte Komponenten verwendet werden, können auch Peptide mit nicht-proteinogenen Aminosäuren in der Bibliothek enthalten sein. Dies kann aufgrund von deren besseren pharmakokinetischen Eigenschaften und der Möglichkeiten zur Zyklisierung vor der Selektion vorteilhaft sein.
Doch auch mit Phagen-Display können zyklische Peptide untersucht und gefunden werden: entweder durch die Zyklisierung über Disulfid-Brücken oder die Verwendung von chemisch modifiziertem Phagen-Display, bei dem Peptide durch chemische Reaktionen auf den Phagen zyklisiert werden (20).


