 |  | Robert Hübner |
| | Hermann Wätzig |
 |
02.03.2025 08:00 Uhr |
Die Zunahme der Leistungsfähigkeit von ChatGPT 4.0 zur aktuellen Version 4o1 (»o« wie omni) zeigt, dass es offensichtlich gelungen ist, die KI modular aufzubauen. Die KI entscheidet auf einer bestimmten Stufe, dass es sich um eine Rechenaufgabe handelt, und übergibt an das zuständige Modul.
Das menschliche Gehirn verfügt über spezialisierte Bereiche für verschiedene Aufgaben wie Sprachverarbeitung, Motorik, visuelle und akustische Wahrnehmung, Geruchssinn, Kurz- und Langzeitgedächtnis, räumliches Denken, Rechnen, Emotionen, Planung und Bewusstsein. Vergleichbar dazu könnte eine zukünftige KI aus mehreren spezialisierten Modulen bestehen: einem Sprachmodul, einem akustischen und optischen Modul, einem logischen Modul, einem Gedächtnismodul für die Datenspeicherung und verschiedenen bewertenden Modulen. Ein Bewertungsmodul könnte beispielsweise die Verlässlichkeit der Aussagen beurteilen und Konfidenzintervalle angeben. Eine weitere Komponente könnte das Modell mithilfe von menschlichem Feedback an die Benutzerwünsche anpassen.
Langfristig ist dies das Ziel: Statt immer größere Universalmodelle zu konstruieren, sollte man spezialisierte kleinere Modelle bauen. Diese könnten die jeweiligen Aufgaben wahrscheinlich besser bewältigen und zudem würde der Ressourcenbedarf deutlich verringert. Deep Seek geht dabei gerade mit gutem Vorbild voran und zeigt, dass es auch mit einem Bruchteil der Ressourcen mit dem bisherigen Marktführer OpenAI mithalten kann.
Ähnlich wie bei Lebewesen Erinnerung und Erfahrung von entscheidender Bedeutung sind, spielt die Datenbasis für die KI eine zentrale Rolle. Die Leistungsfähigkeit selbstlernender Systeme hängt entscheidend von der Qualität der Daten ab, mit denen sie trainiert werden. Die Leistungsfähigkeit von ChatGPT (und damit von Microsoft Copilot und Bing), gemini, Llama, Mistral und neuerdings Deep Seek basiert auf umfangreichen Datensätzen.
Darüber hinaus sind eigene Daten (Content) sehr wichtig. So kann sehr viel Spezialwissen einer Disziplin berücksichtigt werden. In der Pharmazie sind dies unter anderem das Wissen aus Lehrbüchern, der Inhalt der Arzneibücher und Kommentare, klinische Studien und Therapieleitlinien.

© Adobe Stock/PhotoSG
An dieser Stelle spielen Urheberrechte eine große Rolle. Spezialwissen entsteht unter erheblichem Aufwand und Verlage finanzieren sich durch den Erwerb und Weiterverkauf von Autorenwerken. Daher müssten sich KI-Entwickler und Verlage über die Verwendung urheberrechtsgeschützter Werke einig werden. Die Verhandlungen werden voraussichtlich nicht mit der schnellen Weiterentwicklung der KI Schritt halten.
Wahrscheinlicher ist, dass einzelne Nutzer gezielt das benötigte Spezialwissen erwerben, beispielsweise in Form von PDF-Dateien, und in ihrem persönlichen Bereich anwenden. Diese Vorgänge spielen sich dann außerhalb der Kontrolle durch die Urheber des Materials ab. Wenn keine anderen Nutzer Zugriff bekommen, ist die Frage der Urheberrechte nach heutiger Rechtslage nur relevant, wenn im Kaufvertrag etwas über die digitale Nutzung vereinbart ist. Die Informationssuche kann nach wie vor regelbasiert (algorithmisch) auf Basis von Stichwörtern erfolgen, also mit den klassischen Suchfunktionen in Texten. Die Ergebnisse können anschließend von einer KI zusammengefasst und dargestellt werden.
Zudem kann die Methode der Retrieval Augmented Generation (RAG), eingebettet in ein Large Language Model (LLM), eingesetzt werden (Grafik). Derzeit gibt es mehrere konkurrierende Ansätze, und es bleibt spannend, welcher sich als der erfolgreichste erweisen wird.
Der aktuelle Stand der Technik ermöglicht es der KI, als Agent ähnlich einem Bibliothekar zu agieren. Die KI kann eine Liste von Quellen bereitstellen oder dem Nutzer helfen, große Mengen an Antworten einzugrenzen. Dies kann beispielsweise durch die Filterung nach Publikationsjahren oder thematischen Gebieten geschehen, um relevantere und fokussierte Suchergebnisse zu erzielen. Dies hilft den Nutzern, effizienter mit umfangreichen Datenmengen umzugehen und spezifische Informationen schneller zu finden.
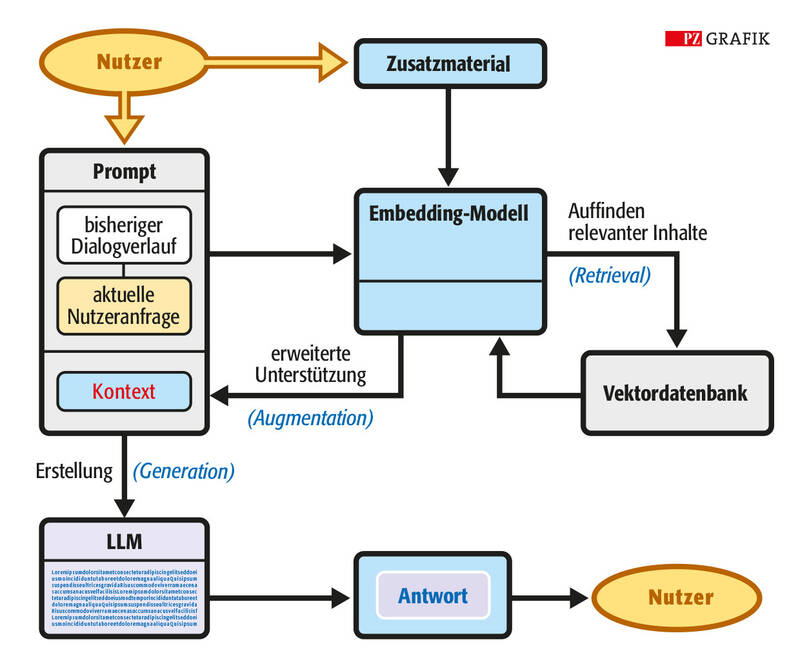
© PZ/Stephan Spitzer
Die Leistungsfähigkeit von künstlicher Intelligenz kann durch den Einsatz spezifischer Kontexte erheblich gesteigert werden. Verschiedene Methoden ermöglichen die Integration spezialisierter Informationen in ein allgemeines Modell. Eine bewährte Technik ist die hier gezeigte Retrieval Augmented Generation (RAG). Dabei wählt der Nutzer relevante Zusatzmaterialien, zum Beispiel Gesetze, Regelwerke oder Lehrbücher, und erstellt aus dem Material mithilfe eines kleineren spezialisierten Sprachmodells, dem Embedding-Modell, eine Vektordatenbank, die sowohl Schlagworte als auch semantisch verknüpfte, komplexere Inhalte enthält. Wenn der Nutzer eine Anfrage stellt, wird diese mit dem Verlauf vorheriger Anfragen kombiniert. Zudem wird die Vektordatenbank nach weiterem relevanten Kontext durchsucht. Die gesammelten Informationen – bestehend aus der konkreten Anfrage, dem bisherigen Verlauf und den spezialisierten Inhalten – bilden gemeinsam den Prompt, der an das große Sprachmodell (LLM) übergeben wird. Dank dieses informationsreicheren Prompts kann das LLM erheblich präzisere und effektivere Antworten liefern.


